MS-TCN++: Multi-Stage TCN for Action Segmentation
0 简介
时序卷积网络(temporal convolutional networks,TCN)由于能够建模时序关系,因而在语音合成领域(Speech Synthesis)中得到广泛的应用。
近年来,也有研究者采用TCN-based的模型来进行时序动作分割任务。但是这些方法依赖于时序池化操作(temporal pooling)来增加感受野(receptive field),导致时序分辨率降低了,因而丢失了许多识别需要的的细粒度信息(fine-grained)。
为了解决上述问题,本文提出了一个多阶段时序卷积网络(Multi-Stage TCN),在每一阶段都给出一个初步的预测,然后在下一阶段进行微调。
MS-TCN
与之前方法类似,MS-TCN同样采用了时序卷积操作进行时序关系的建模,不同之处在于MS-TCN没有采用池化操作,因而可以在全分辨率下建模帧与帧之间的时序关系。
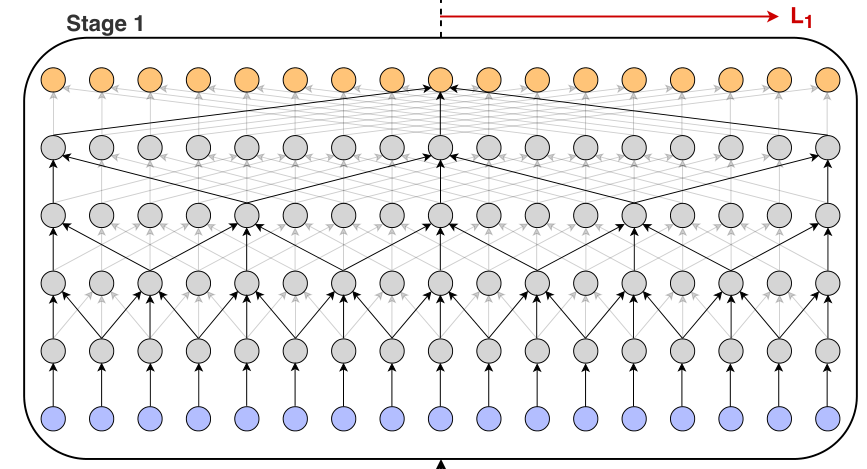
MS-TCN由几个阶段(Stage)构成,每个阶段输出一个预测,这一预测由下一阶段进行优化。在每一阶段内,一系列的膨胀残差层(dilated-residual layer)作用于输入的特征。后一层的膨胀系数是前一层的两倍。膨胀系数残差层如下图所示:
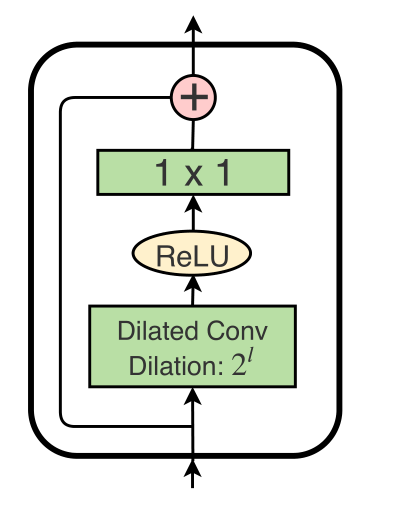
因而MS-TCN使用了较少的参数获得了较大的感受野。同时,为了防止过分割(over-segmentation),作者在每一个阶段后加入了一个平滑loss作为监督信息,MS-TCN示意图如下:
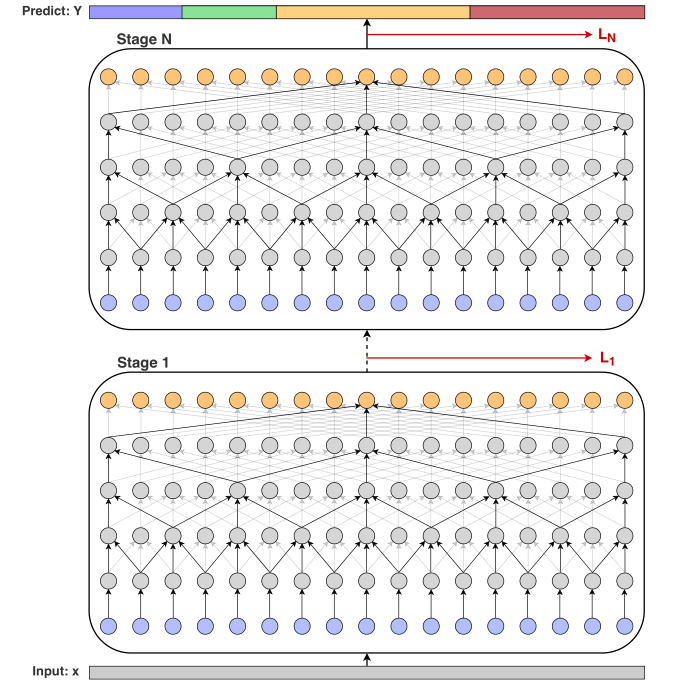
MS-TCN++
尽管MS-TCN已经取得了不错的精度,但是一些设计仍然还有改进空间:
- 在MS-TCN中,高层有较大的感受野,但是低层的感受野仍然很小;
- 在MS-TCN中,第一阶段是用来生成初始预测的,后面的几个阶段是用来调整这个预测的。尽管是两个不同的任务,但是在MS-TCN中它们却共享同样的结构。
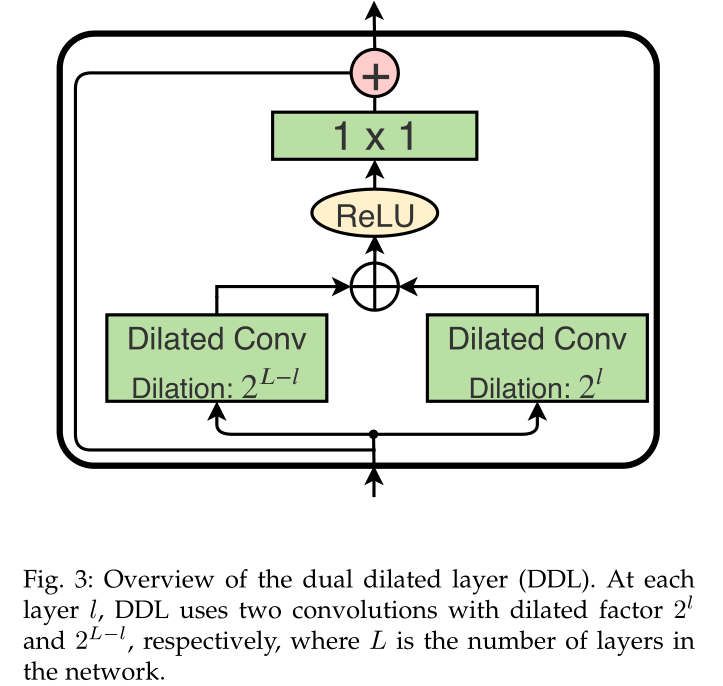
针对第一个问题,作者使用了双重膨胀层(dual dilated layer,DDL),它在每一层都结合大的感受野和小的感受野,使得不同层不同尺度的信息可以融合;
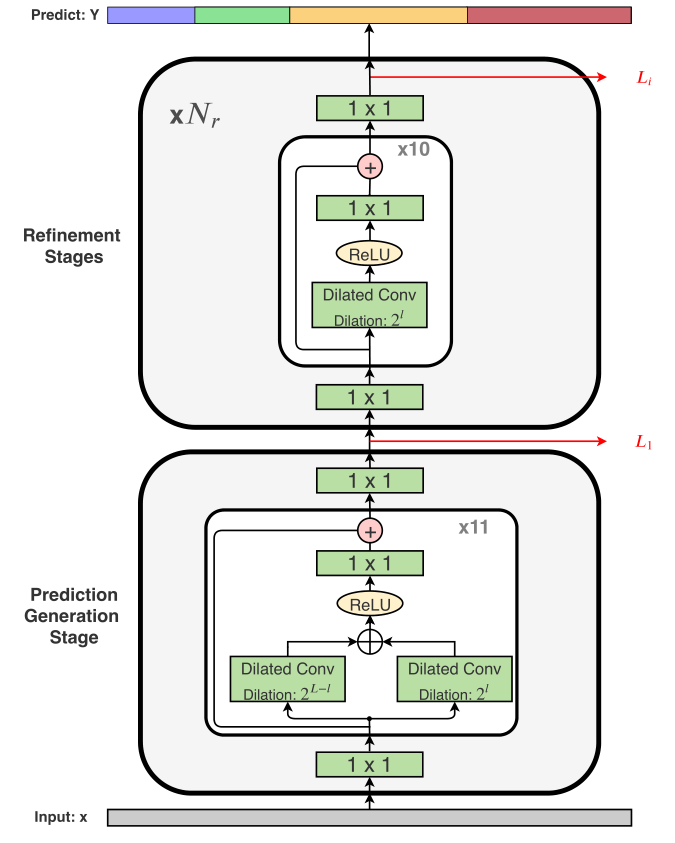
针对第二个问题,作者解耦设计第一个阶段和其余阶段,使得不同的阶段能够适应不同的任务。因为生成初始预测比调整预测更加复杂,因为第一阶段需要更为复杂的设计。该研究发现,由于后几个阶段的任务是相同的,这些阶段的参数也可以共享,进一步降低参数量。
1 方法细节
Single-Stage TCN
第一层是一个1x1的卷积层,用来调整输入特征维度,以匹配模型的feature maps number ;
然后紧接着是几层一维的膨胀卷积层,且每一层后的膨胀因子会翻倍:1,2,4,…,512。其中,每一层的卷积核数目相同,且大小都为3。
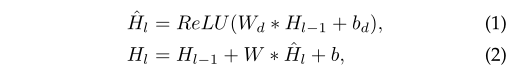
其中, $W_d \in R^{3 \times D \times D}$ 是卷积核大小为3,卷积核数目为D的膨胀卷积核的权重; $W \in R^{1 \times D \times D}$ 是 $1 \times 1$ 卷积的权重, $b_d,b \in R^{1 \times D \times D}$ 是这个 bias。操作如下图所示:
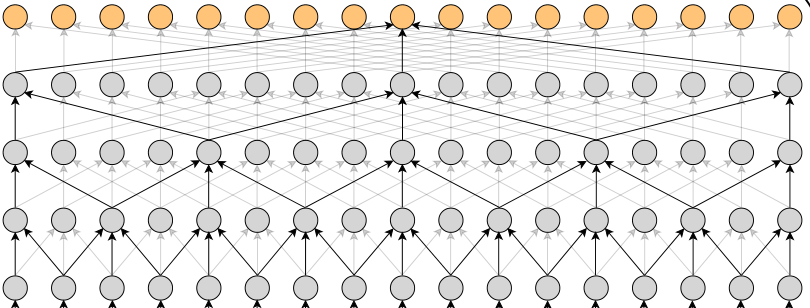
使用卷积核大小为3,膨胀系数逐层倍增的膨胀卷积核,我们能在几个卷积层内就获得比较大的感受野:
$$
ReceptiveFiled(l) = 2 ^{l+1} - 1, where \quad l \in [1,L]
$$
假设第$i$层的膨胀系数为 $d_i$,感受野大小为$R^i$,则有:
$R^i = 2^n + R^{i-1} = 2^{i+1}-1$
$$
d_i = 2 * d_{i-1}=2^{i-1}\
R^i=1+d_i \times (k-1)+(R_{i-1}+1)/2 \times 2 \
=2 \times d_i+R^i=R^i+2^i\\
\implies R^i = 2^{i+1}-1
$$
如下图:
最后,为了得到每一帧的类别分布,我们在最后一个膨胀卷积层后面添加一个Softmax层:
$$
Y_t = Softmax(Wh_{L,t}+b)
$$
Multi-Stage TCN
我们将单阶段的TCN扩展为多阶段的TCN来完成时序动作分割任务,第一阶段用于产生初始预测,后续阶段用于对这个预测进行微调;
$$
Y^0 = x_{1:T} \
Y^s = \mathcal{F}(Y^{s-1})
$$
其中,$Y^s$是第$s$阶段的输出,$\mathcal{F}$是之前描述过的SSTCN;第一阶段的输入$Y^0$是视频的frame-wise features,后几个阶段的输入都是上一阶段产生的 frame-wise probabilities。而由于每个阶段的输出是一个初始的预测,所以网络能够捕捉动作类之间的依赖关系,并学习合理的动作序列。
我们逐层倍增膨胀系数,但是这会导致这样的几个问题:
- 高层有很大的感受野,但是低层的感受野依然很小;
- 由于大的膨胀因子,较高的层在非常遥远的时间步长上应用卷积;
所以,我们提出了双路膨胀卷积层(dual dilated layer),在每一层都是用两个膨胀系数的膨胀卷积。
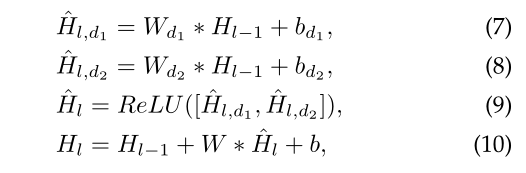
其中$W_{d1},W_{d2} \in R^{3 \times D \times D}$是膨胀卷积核权重,其膨胀系数分别是$2^l,2^{L-l}$;$W \in R^{1 \times 2D \times D}$是$1 \times 1$卷积核的权重。$b_{d1},b_{d2}$是bias。具体形式如下图所示:
在一些文献中,也有使用特征金字塔网络(Feature Pyramid Networks)进行多尺度特征融合的,但是这种方法的感受野依然受限,而且在FPN中多尺度信息是通过池化操作得到的,这会损失时间分辨率,丢失在时序分隔中可能需要的细粒度信息。
Multi-Stage TCN++
与MSTCN不同的是,MSTCN++在第一阶段(用于产生初始预测的阶段)使用带DDL的SS-TCN,而在后续阶段仅仅使用普通的SSTCN。主要是如下考虑:
- 在产生初始预测的时候,使用DDL可以让我们同时利用 local and global 的特征,这些特征在后面的SS-TCN阶段也可以被继续使用;
- 考虑到对预测进行refinement可能比产生初始预测要简单一点,所以我们在后续的阶段都是用带一个膨胀系数的卷积操作;
- 在我们的实验中,也可以看出只在第一个阶段使用DDL表现的更好;
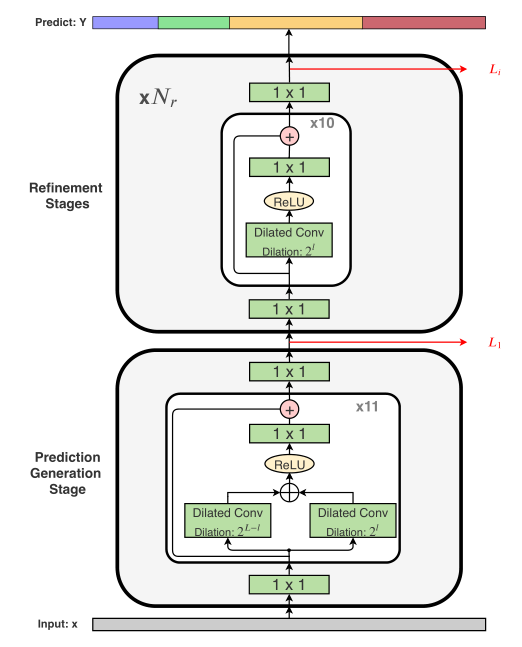
由于后面的调整阶段的作用都一样,所以我们让其共享参数,这样可以大大降低模型参数量,而且只有少量的精度损失。
Question
在MS-TCN中第一阶段的输出经过线性映射和Softmax层了吗?还是只是产生一个膨胀卷积层的输出用于下一阶段的输入,这样比较合理一点。
A:通过目前来看好像每个阶段都会产生一个概率分布,然后送进下一阶段进行微调,微调的阶段网络可以捕获到动作类别之间的依赖关系,所以微调阶段的网络和产生初始阶段的网络不一样。
Loss Function
使用分类损失(classification loss)和平滑损失(smoothing loss)的结合:
- 分类损失使用交叉熵损失:
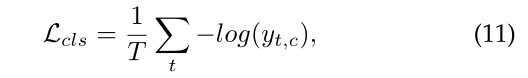
虽然交叉熵损失表现的很好,但是我们发现在对某些视频产生动作分割预测的时候会出现over-segmentation问题,所以我们又添加了额外的平滑项:在frame-wise的log-probabilities中使用一个截断的均方误差:


这个平滑项目类似于一个KL散度(Kullback-Lebler divergence),但是在实验中我们发现截断的均方损失在解决过分隔问题上要表现的好一点。

最后单阶段的损失如下:

多阶段的损失取个总和:

2 实现细节
MS-TCN和MS-TCN++都包含4个阶段,其中MS-TCN中的4个阶段相同,但是MS-TCN++由一个预测阶段和三个微调阶段组成。MS-TCN的所有阶段和MS-TCN++的微调阶段使用10层的单尺度膨胀卷积层,MS-TCN++的初始预测阶段使用11层的双尺度膨胀卷积层。如下图所示:
- 每一层后我们使用失活概率=0.5的Dropout层;
- 所有层的卷积核数目d=64,卷积核大小为3;(d=64是不是意味着要调整模型的特征维度为64???)
- 损失函数的超参数 $\tau = 4, \lambda = 0.15$;
- 优化器选用Adam,学习率设置为0.0005;
3 消融实验
选用50Salads[^1],GTEA[^2],Breakfast[^3]数据集,并提取I3D的运动特征作为模型的输入,并且视频的时序分辨率定位 $15 fps$。

评价指标:
- frame-wise accuracy(Acc)
- segmental edit distance
- segmental F1,其中overlapping thresholds(通过交并比IoU计算)设为 $10\%,25\%,50\%$,记为 $F1@\{10,25,50\}$。
阶段数目的影响

- 所有的模型在Acc上的表现都相当,但是预测的质量确实不同的;
- 通过segmental edit distance 和 F1 scores可以看出来,单阶段的模型出现了更多过分割的错误(F1很低);通过添加更多阶段,我们可以对初始预测进行微调,因为微调阶段可以建模之前初始预测动作类间的依赖关系,然后可以进行调整,减少过分割。

- 当阶段数目加到5时,可以发现精度出现了下降,原因可能是由于模型参数量的提升出现了过拟合的现象;所以,后面我们的实验基于4阶段的MS-TCN进行。
MS-TCN 还是 Deeper SS-TCN
上一节表明多阶段的TCN比单阶段的表现好,然而,这种比较并没有显示出这种改进是由于多阶段架构,还是由于添加更多阶段时参数数量的增加。所以,我们用一个4阶段的MS-TCN跟一个有着48层同等参数量的SS-TCN比较:

Quesion
个人感觉是不是因为MS-TCN添加了残差连接导致的模型效果上升,只是作者把这种行为定义为多阶段预测,其实MS-TCN也就相当于带有残差连接的深度SSTCN???
A:但是其中有一点不一样的是如果是带有残差的SSTCN就是只会产生一次概率预测,但是MS-TCN是产生概率预测后不断对概率进行微调。
不同损失函数的比较
- 与交叉熵损失相比,平滑损失略微提高了帧的精度,但我们发现这种损失产生的过分割错误要少得多。因为它迫使连续的帧具有相似的类概率,从而导致更平滑的输出。
- 截断的均方损失比KL散度表现要好,因为在目标概率和预测概率之间的差异非常小的情况下,KL散度损失并不会受到惩罚。

- 注意,与KL损失相反,提出的损失是对称的。下图显示了两类情况下的KL损失和提议的截断平均平方损失的形状。我们也尝试了KL损失的对称版本,但它的表现比KL损失更糟。

λ and τ 的影响


- λ :对性能的影响比较小(可能是因为这里的$\lambda$都设置的比较小),但是过大的λ可能会影响模型检测action segments间的boundaries.
- τ:设置为5会导致性能的巨大下降,因为当τ过高时,平滑损失惩罚了“模型非常确信连续帧属于两个不同类别”的情况,这确实降低了模型检测动作片段之间真实边界的能力。
传递特征给更好层的影响
在human pose estimation的多阶段结构中,额外的特征通常会和上一阶段的heat-maps进行concatenated作为下一阶段的输入,所以我们实验这样的方式对我们的任务是否有效。
因此,我们实验了两个MS-TCNs:
- 一个模型将前一阶段预测的frame-wise probabilities作为下一阶段的输入;
- 一个模型将之前所有阶段最后一个膨胀卷积层的输出进行concatenated,作为下一阶段的输入;

如上表,对特征进行concatenated将造成F1值和Edit distance下降,原因可能是:
许多action classes 具有相似的外观和动作特征,如果模型将每一阶段关于这些classes的特征都加进来,可能让模型变得很疑惑,产生小的分离错误检测的行动段,导致过分割错误。

Question
会不会是因为对特征进行Concatenated而不是像ResNet那样进行add,导致模型参数过多,过拟合了。
MS-TCN++还是 MS-TCN

- 使用DDL后,MS-TCN with DDL(每一阶段都使用DDL)和MS-TCN++都有一定的精度提升,表明在产生预测阶段融合局部特征表达+全局特征表达的重要性;
- 但是MS-TCN++的效果要好一点,说明了使用DDL融合全局特征在预测阶段是更加重要的,但是在微调阶段可能更加注重局部的相关关系。(也有可能是过拟合了,但是比起不加确实会有提升)
- DDL的作用在下图能够看出来,能够比较好的区分相邻的action segment,较少不必要的误判;

层的数目的影响


在短视频上大的感受野的影响

MS-TCN和MS-TCN++在短视频和长视频上表现的都比较好,但是当视频长度变长后,由于感受野的限制,性能有一些下降。
微调阶段数目的影响

参数共享的影响

时序分辨率的影响

特征fine-tune的影响

微调的I3D特征会使得性能有一定的提升,但是动作分割的微调效果低于动作识别,可能是分隔中时序模型更重要一点。
和SoTa模型的比较


- 以上的结果都是基于I3D产生的;
- 为了研究不同特征的影响,我们在Breakfast数据集上使用了IDT特征,发现不同特征的影响很小;
- I3D特征同时编码运动和外观,而IDT特征只编码运动。但是对于像Breakfast这样的数据集,使用外观信息对性能没有帮助,因为外观不能提供有关所进行的动作的有力证据。如下图所示,Breakfast的场景非常类似:

- 由于我们的方法不使用任何RNN层,因此在培训练和测试过程中都非常快;
4 总结
本文提出了一个多阶段模型来解决视频动作分隔问题:第一阶段用于产生预测,然后在后续阶段对预测进行调整。同时,没有使用temporal pooling操作,而是使用膨胀卷积来获得不同时间尺度的信息,而且使用DDL层来融合不同时间尺度的信息。
模型是全卷积操作,在训练和预测时候都很快。
[^1]: “Combining embedded accelerometers with computer vision for recognizing food preparation activities,” in ACM International Joint Conference on Pervasive and Ubiquitous Computing, 2013, pp. 729–738.
[^2]: “Learning to recognize objects in egocentric activities,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2011, pp. 3281–3288.
[^3]: “The language of actions: Recovering the syntax and semantics of goal-directed human activities,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp.780–787.
[^ 4]: “Temporal convolutional networks for action segmentation and detection,” in IEEE Conference on CVPR2017.


